2026 法鼓數典專案春季成果發表會,已於 5 月 20 日下午圓滿落幕。該場盛會計有近 90 位參與者共襄盛舉,相約線上雲端,一齊聚焦佛教文獻數位化及人工智慧的最新應用成果。
(一)跨譯本視野下的《解深密經》──資料庫建構與文本研究
首度面世的《解深密經》資料庫,是「唯識典籍數位資料庫」的第五塊計畫拼圖。發表人法鼓文理學院蔡伯郎教授表示,本資料庫收錄了《解深密經》的四種漢譯本、一種藏譯本,並加入古德注疏及文本譯詞對應、藏文字詞解析等參考資源。透過更整全的文獻資料,及更便利的對讀系統,期使裨益讀者們能更深入理解這部唯識學派的重要經典。
未來,本資料庫將提供 DOCX 檔下載與編輯服務,並廣納專業意見,針對既有文獻資料做更精確的修訂與擴充解釋。本場尾聲,蔡老師並邀請大家一同參與線上剪綵儀式,在溫馨、愉快的氣氛中結束本場次發表內容。
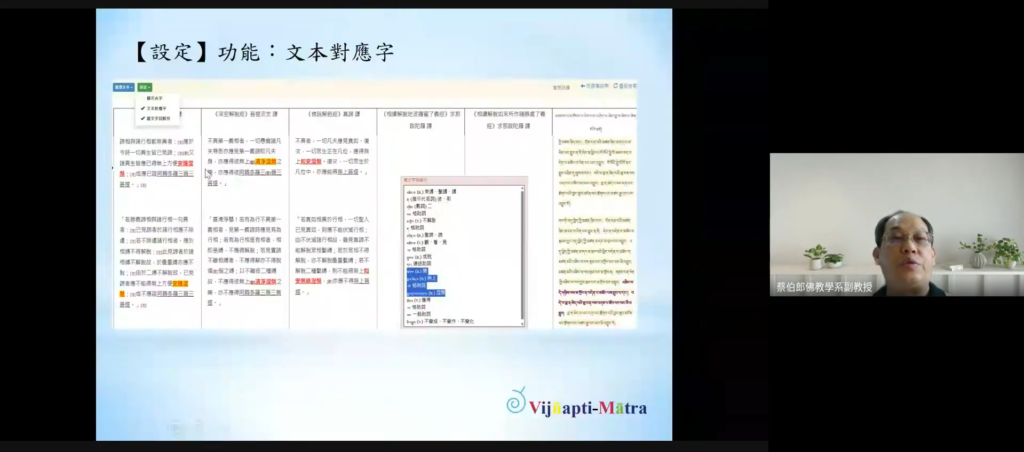
(二)早期佛教文獻學之數位平台:安止天《俱舍論註雜錄》經典引文資料庫
藏譯佛典安止天《俱舍論註雜錄》,收錄有五百餘筆《阿含》引文,此諸經文的梵本已部分甚至完全佚失,是以該作被認為是重構《阿含》經文的重要文獻。
發表人德圓法師說明,本資料庫的核心功能計有三項:(一)「614 筆引文資料庫」,提供該作所引《阿含》經文的完整資料。(二)「平行文本索引」,提供《俱舍論》梵、藏本,相關《阿含》巴利、漢譯等多種平行文本的對照。(三)「藏經對勘全文」,提供該作六個藏經版本的對勘及頁碼行號等出處資訊。
本資料庫亦收錄《稱友疏》的相關段落,並整合本庄良文日譯本等重要文獻,並建置《阿含》經文與 CBETA Online 頁面快速連結的功能,裨便讀者瀏覽、查詢。
另外,計畫團隊也照顧到數位工具的應用,首先善用 Dharmamitra 的翻譯功能,結合大型語言模型的操作,將可以大幅縮短獨立探索的時間,快速獲取相關背景資料,及各經論間的互文參照檢索資訊。
團隊並將資料庫所提供的完整標記文本,結合 Obsidian、Claude Code 等數位筆記及人工智慧工具,建立引文與經論之關聯圖譜。透過知識圖譜的建立,我們即可透過觀察核心結點網絡,清楚掌握《俱舍論》的核心教義觀念,即其與《阿含》關聯的知識體系。
未來資料庫將持續更新更多的相關研究成果,並開放 TEI 標記之 XML 原始檔,以擴展研究運用。


(三)從詞典到知識:利用大型語言模型建構佛教知識圖譜
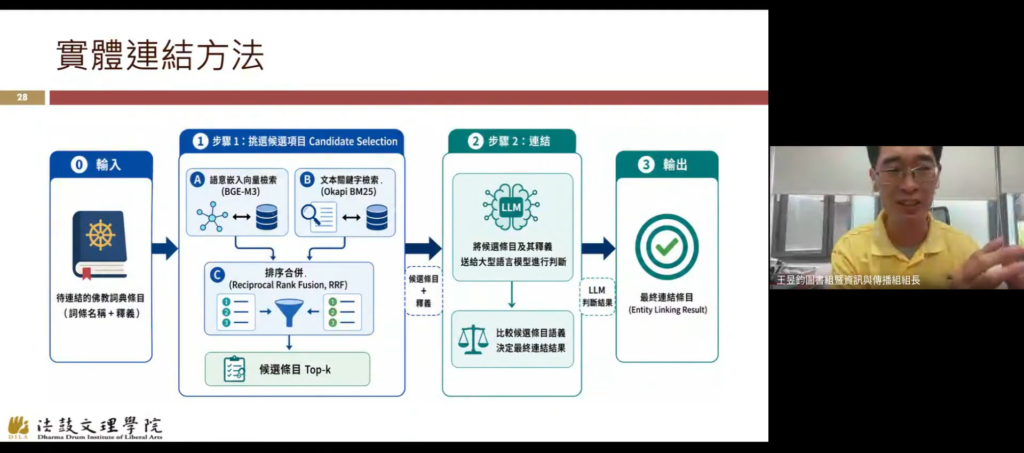
本場發表人王昱鈞教授解釋,「知識圖譜」是將知識以結構化的關聯形式表達,其核心為「實體—關係—實體」(Entity-Relation-Entity)組成的「三元結構」。這種將知識實體化的實踐,可以提供機器可計算、結構化的語意結構,進而支援進一步的理解與搜尋。
而面對佛教文本所具備的多層次語義結構,知識圖譜除了可以幫助將知識以結構化的方式保存外,也具備可視化的特徵,更重要的是,將促進佛教體系內,如經、史、疏、傳之間,跨文本間的推理功能。影響所及,將有助於學術研究、數位人文工具實踐、人工智慧應用等多項層面。
而因應知識圖譜建構的高門檻,詞典所具備的「詞條名稱」(實體)、「詞條定義」(語意內容),則適巧提
供了建立知識圖譜所需的重要材料。團隊透過將多部詞典的「義象合併」、「摘要與與改寫」、「義項語義分類」、「關係擷取與驗證」,再經由「S-P-O 三元組擷取」,最終「取得實體連結」六項步驟,建構佛教知識圖譜的新途徑。
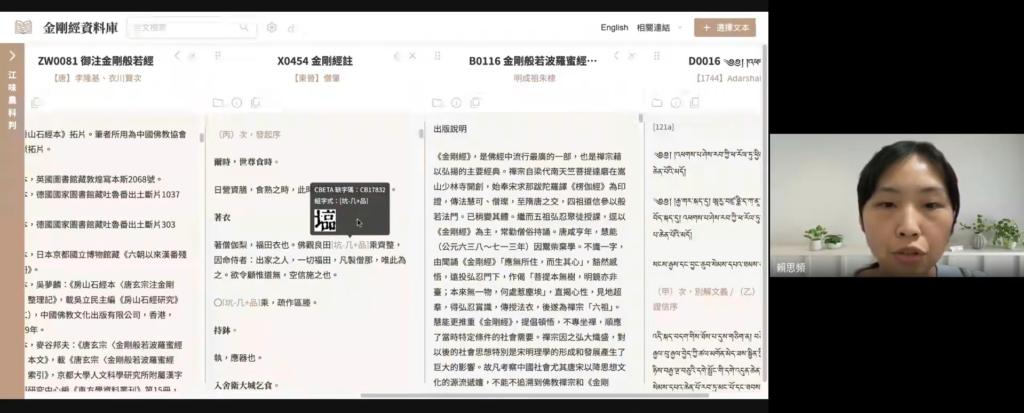
(四)金剛經論註疏對讀系統——數位工具與佛典詮釋的新對話
金剛經多語經論注疏資料庫 屬於江味農居士紀念網站計畫的一環。發表者江味農專案資訊工程師賴思頻表示,本資料庫依江味農居士所著《金剛經講義》中的〈科判〉為架構,串聯彙整異地、異時、多語的《金剛經》經論注疏之作。綜觀其成果,目前共收錄有 20 部文本、跨越 3 種文本語言、4 種文本類型;並持續累積收錄文獻中。
核心功能方面:透過(一)「多版本經文同步對讀」,整合原先散落於不同平台的《金剛經》注疏文本,同時有效解決傳統紙本時代,難以同時對讀諸本的窘境;倚重(二)「科判的視覺化導引」,引領使用者一方面藉由〈科判〉之作,綱舉目張地把握諸本經論注疏的要義與異同處,同時打造視覺化、可互動的數位呈現。
另,資料庫網站又有六項輔助功能,分別為:(一)各文本的「目錄結構」,利於快速點閱、瀏覽;(二)持續建置中的「Metadata 清單」,以提供更豐富,劃一的後分類資料成果;(三)一鍵「引用複製」;(四)「全文與科判檢索」,能就著科判及當前頁面上的文本資料,進行全文檢索;(五)「顯示設定」,調整若干功能細節;(六)指定想閱讀的文本,並一鍵「分享連結」。
未來在內容上,將持續擴充收錄文本,也會嘗試把科判對讀的這套架構,延伸至其他經典,發展通用經典的閱讀架構。網站服務方面,則會朝個人化的功能發展,與導入 AI 智能技術,提升讀者的使用體驗。
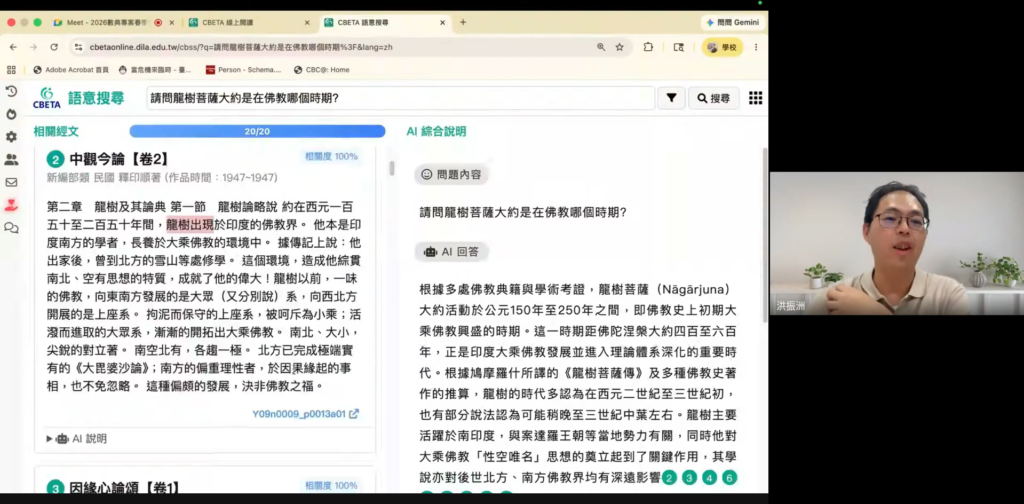
(五)從關鍵詞到語意:CBETA 搜尋功能的演化與發展
本場次發表人為法鼓文理學院圖書資訊館館長,同時也是 CBETA 執行長的洪振洲教授。在進入正式主題發表前,洪教授快速盤點了去年至今年,CBETA 所新增的各項重要功能:包含使用者敲碗已久的(1)DOCX 文件格式下載功能;(2)整合 Dharmamitra AI 翻譯服務、(3)語意搜尋的開發,協助讀者突破語言、語意的隔閡,更快找到欲尋找的佛典文本;(4)新推出 版本修訂歷史查詢 網站,詳述佛典修的依據與原因,以昭公信。
此次發表主題,則聚焦於「搜尋」一事。
眾所周知,全文搜尋是一種基礎且必要的功能。CBETA 自 1998 年推出單機版起,即照顧到這項使用需求,在至今仍持續更新的單機版中,我們依舊可以善用全文搜尋的功能,以少於 0.1 秒的搜尋速度,快速過濾、篩選出自己想要尋找的資料。
然而,面對層疊積累、數量龐大的佛典文獻,僅依關鍵字搜尋是有其侷限的。實務上至少會有以下的四大挑戰。
(1)「一詞多義遇上海量文本」,將導致搜尋結果暴增,無法聚焦特定範圍的搜尋成果;(2)「字形的變異」、(3)「詞語變化」,各種不同的譯名、專有名詞的差異,將導致使用者被阻隔於文字、語詞的關卡;(4)「關鍵字的隔閡」,直觀、一般日常語境下的關鍵字,往往與佛教體系內的用語不同,會造成義理層面的搜尋困難。
而 CBETA 持續更新後所完備的搜尋功能,正是為了對治了這些不同的痛點而應運而生。
其實踐方式如下:首先,CBETA Online 顯示搜尋結果時,會同時呈現上下文,亦即「以 KWIC (Keyword in Context) 方式呈現」。此外,讀者可依不同的「後分類」進行搜尋過濾,並顯示搜尋結果在這些類別的分布,如此能消除(1)「一詞多義遇上海量文本」的使用窘境。
而 CBETA Online 的「異體字建議」功能,是在搜尋之際,以系統自動偵測並顯示搜尋欄內的可能異體字,進行替代與顯示相關搜尋建議,幫助使用者跨越(2)「字形的變異」關卡;而系統借助 Smith-Waterman 演算法所推出的「相似段落查詢」功能,則能有效解決(3)「詞語變化」的困難。
最後,團隊使用大語言模型,以「意義比對」為基礎,協助使用者穿越關鍵字的屏障,直接找到佛典中的意義段落,此即「語意搜尋功能」。藉此打破(4)「關鍵字的隔閡」,探驪得珠。
在未來的發展方面,由於執行「語意搜尋功能」會花費較多的查詢時間,以及伴隨而來的金額支出,故如何降低使用外部大型語言模型的成本,將是一項重要目標;同時,CBETA 也計畫探索更進階的架構,如推理模型(Reasoning Models),以促進其回答品質的上升。

(六)從鸚鵡到鏡子——一場讓 AI 照見本來記憶的佛典大考
在人工智慧工具高度普及的此刻,「有事問 AI」似乎成了多數人的日常。然而,究竟現在市面上常見的人工智慧工具,如 ChatGPT、Claude 等,對佛典的掌握度,是否有隨著一代代的模型更新而提高,從而避免幻覺呢?而經典的「常用」與否,是否會影響 AI 答題的表現呢?研究團隊即懷抱著這樣問題意識,開啟「一場讓 AI 照見本來記憶的佛典大考」。
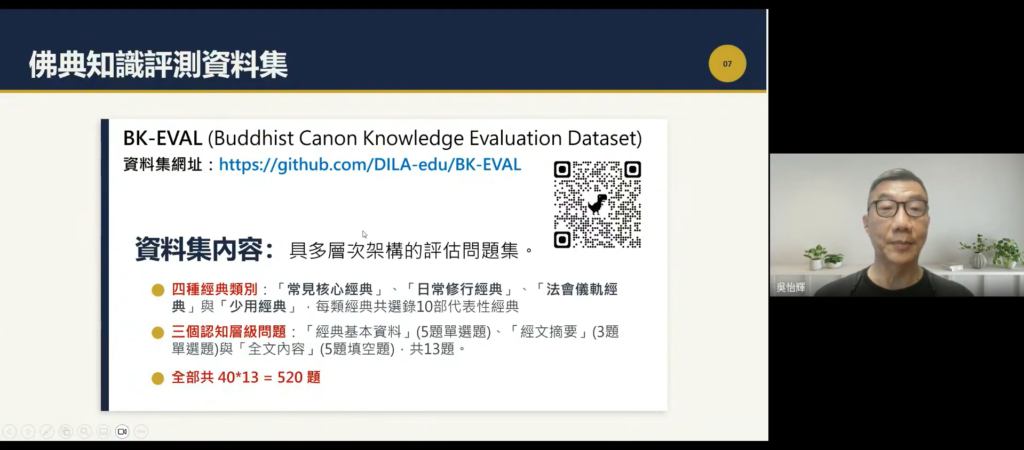
本場發表人法鼓文理學院數位典藏組專案助理吳怡輝表示,團隊設計了一套具有多層次架構的 佛典知識評測資料集BK-EVAL (Buddhist Canon Knowledge Evaluation Dataset) ,此中包含「四種經典類別」(「常見核心經典」、「日常修行經典」、「法會儀軌經典」、「少用經典」,每類選錄 10 部代表經典),再加上「三個認知層級問題」(「經典基本資料」、「經文摘要」、「全文內容」),共計 520 道題型,進行測試。過程中,並要求 LLM 在不得引用外部資源(如網路、資料庫、API)的情形下,使用「模型內建的參數記憶」來回答資料集內的問題。
評估對象方面,相較於去年 DADH 2025 時,僅使用 GPT、Claude 等共計 6 種模型,本次春季發表會則使用了目前線上最新的模型,外加新增 Qwen3.5-35B-A3B、Gemma-4-E4B-it,總共 11 種模型。
根據這兩次的測試,團隊發現幾項值得注意之處:首先,LLM 對佛典的記憶可謂與日俱增,關於常見經典的摘要與背景的回答,應該可信。其次,問答若牽涉經典全文內容,最好採用旗艦型 LLM,其來源若為常見經典,也會較為可信。而 LLM 在摘要項目回答得最好,推測原因都跟所提供的資訊較多有關。
團隊未來預計會再增加罕用經典測試項目,繼續測驗 LLM 的邊界。
以上就是本次 2026 法鼓數典專案春季成果發表會 所有發表場次的會議內容簡述。發表結束後,與會聽眾又針對進一步的細節內容提出了許多問題,討論非常熱烈,當日直到下午五點才圓滿結束。歡迎無論是想補課,或是複習會議內容的好朋友們,歡迎點閱 DILA 在 YOUTUBE 頻道的 完整錄影 喔!
